This week we dig into the procedures that power the NRS Web Continuity Service. We are a multi-faceted service, dealing with numerous stakeholders and subject areas. With that in mind, we need to ensure our processes are efficient and effective, to help us deliver a high quality web archive.
But what do we mean by ‘high quality web archive’? In web archiving, quality can be related to three elements:
- Completeness – how much of captured website’s links, text, downloads etc. the crawler has been able to access and capture
- Behaviour – how much of the navigational functionalities within the captured website snapshot have been preserved, compared to the live site
- Appearance – how much the design, ‘look and feel’ and user experience of the website has been captured and preserved. We find the quality assurance principles articulated by the NYARC consortium very helpful for this, see https://sites.google.com/site/nyarc3/web-archiving/quality-assurance/introduction
But web archiving is technically complicated. Therefore, ‘quality’ can only feasibly be delivered through refined, consistent processes.
Consistency is key, so to help with this we use the principles of ‘Lean’ process methodology and ‘Parsimonious Preservation’ to guide our work. What this means in practise is that we analyse our service’s processes as a model, identify its beneficiaries, pinpoint where we can inject effort to generate the most benefit, and carry this out.
Stripped back to basics, the NRS Web Continuity Service process model looks like this:
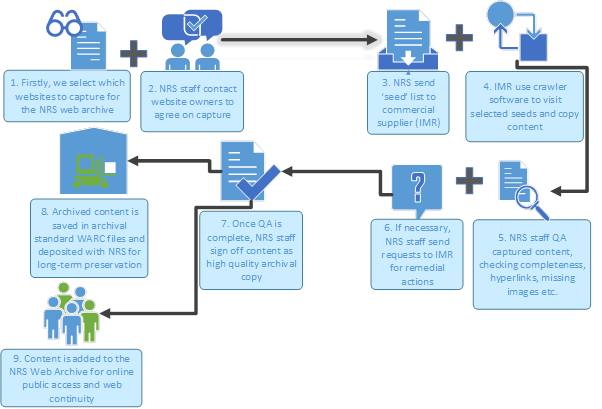
Let’s break this down a little, and describe how we aim for consistency across this model.
- and 2. SELECTION – review and client engagement
As highlighted in our third blogpost, the scope of the NRS Web Archive reflects our statutory and strategic collecting remit. We aim to capture the website of every organisation, or ‘client’, who deposits their archival records with us.
This can be complicated by the fact that websites can be built for different business functions and for varying reasons, meaning that many of our clients own and maintain more than just one website.
Often these ‘secondary sites’ such as https://www.scotblood.co.uk/ (maintained by NHS National Services Scotland) and https://www.globalscot.com/ (Scottish Enterprise) contain rich, unique contextual evidence of their parent organisation’s business, and are of significant archival value. Furthermore, some of these sites may only be maintained for a finite period, so how can (or indeed should) the web archive respond to this?
To help inform our decision making on whether to capture these sites , we listen to our clients – who know their websites better than anyone – for advice on which sites to archive and when to do so. Part of this conversation relates to how frequently sites are captured – is once a year enough to capture a representative copy of the site, or do we need to crawl more frequently than that, to meaningfully archive a site which may be large and changing? We consider the following factors when deciding this:
- Is the website owned by a Scottish public organisation, who have or are scheduled to transfer their archival records to NRS?
- Is the website the main corporate site of the organisation?
- Is information on the website unique?
- Is the majority of the information on the site (>50%) available in the in public domain, or does a lot of information sit behind a paywall/firewall/password/user portal?
- Is the majority of information on the site (>50%) reachable via static hyperlinks/sitemap, or is a large proportion of it dynamically generated and/or available via streamed media?
- Who is the copyright owner of information on the website?
- Is the website due to be closed or heavily redeveloped in the near future?
As a final aid to this process, our Web Continuity Working Group, made up of NRS staff and external stakeholders, meet quarterly to advise on selection and monitor service benefits. This allows us to create an informed and reflective ‘seed’ list for capture.
- and 4. CRAWL
We use the services of our commercial supplier, Internet Memory Research (IMR) for the technical parts of web archiving. We enter details of seeds into a web application to instruct IMR’s crawlers to visit these seeds at a scheduled date. We use IMR’s service to capture 230 snapshots per annum, and crawls are scheduled every month.
- and 6. QUALITY: how we try to deliver this
Crawling a website can take up to four weeks, and once complete, IMR undertake minimum quality assurance (QA) and pass captured content to us.
NRS staff then inspect and analyse this content through our own QA process. We spend no less than 30 minutes, and no more than 3 hours reviewing every snapshot, and then we liaise with IMR on where we detect content gaps or faults. IMR can then undertake remedial actions to try and fix these issues, or alternatively provide guidance for us to pass on to our clients to aid the archiving process.
Further detail will be published on this in the coming months, but our goal throughout is to deliver complete, high quality archive snapshots. This attention to detail is helping us accomplish that.
- and 8. PRESERVATION- sign off and transfer
Once QA is complete, we instruct IMR to preserve archived content in WARC files, which are then transferred to us for their permanent preservation in our digital repository.
- ACCESS – direct access and web continuity
Archived content is then made available for user access at http://webarchive.nrscotland.gov.uk/. We will delve into the ways that users can access our web archive in our final blog post.
The archiving and access process, from the date the crawl is launched through to public access, takes around 8 weeks.
Using a commercial supplier allows NRS staff to focus on the areas which only we can do: selection, client engagement and quality assurance , while our supplier focuses on what they do best: the technical elements of capturing websites. We have developed an excellent working relationship with IMR in a short period of time, and are constantly learning on the job.

One thought on “Aiming for quality: selection, capture, QA and preservation of the NRS Web Archive”